

LSF版本介绍
LSF Suit Community Edition,是LSF官方的社区版,最多支持10节点,每个节点最大2C;
Openlava为 LSF分支开源版本;
IBM Spectrum LSF 与功能套件:
LSF IBM Spectrum LSF Suites :正式版为收费产品,包括IBM Spectrum LSF基本功能以及一些高级功能,例如并行作业管理和自动预测;
IBM Spectrum LSF Application Center :提供了一个可视化的用户界面,使用户可以更轻松地管理和部署应用程序
IBM Spectrum LSF Explorer : 是一个基于Web的图形用户界面(GUI)工具,提供了LSF集群的综合视图,包括作业、节点、队列和其他资源的状态。用户可以使用LSF Explorer提交和管理作业、查看实时状态更新、监视和故障排除LSF集群,并配置和自定义LSF环境。
IBM Spectrum LSF License Scheduler : 是一个许可证管理工具,可帮助用户管理IBM Spectrum LSF集群上的软件许可证。
IBM Spectrum LSF Process Manager :负责管理作业调度、资源分配、进程启动和监控等功能。
IBM Spectrum LSF RTM :提供了实时监控和分析集群性能的功能,以便更好地调整集群资源,优化任务执行效率和响应速度。
LSF集群架构设计
LSF 10.2社区版搭建笔记-陈锐
参考链接:http://www.rchen.top/?p=541
官方配置文档:https://www.ibm.com/docs/en/spectrum-lsf/10.1.0?topic=files-lsbqueues
LSF集群一般由访问节点,访问网络,登录节点,管理节点,计算节点,管理网络,计算网络,存储网络,存储节点,等组成。
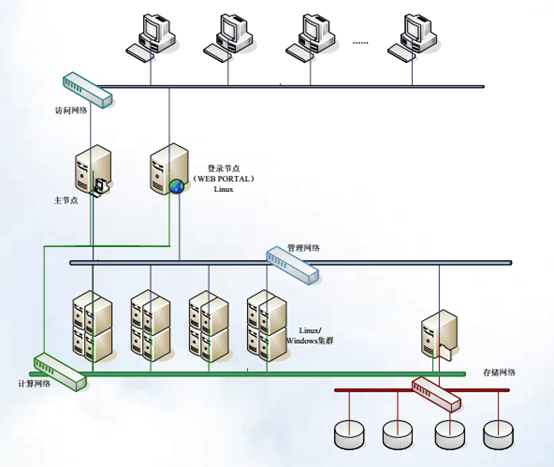
访问节点:通常是用户终端或者虚拟桌面等;
登录节点:Linux登录服务器,此节点需要加入到LSF集群中,用户在登录节点提交LSF作业;
管理节点:作为LSF master服务器;
计算节点:用于lsf提交作业后的程序运行节点;
存储节点:nfs存储节点,负责存储系统的共享;
管理网络:服务器带外管理网络;
计算网络:登录、计算、管理节点之间的流量网络;
存储网络:存储与服务器之间的流量网络;
LSF用户
常用的操作指令
官方操作文档:https://www.ibm.com/docs/en/spectrum-lsf/10.1.0?topic=reference-command
bjobs 检查提交作业状态
bjobs – w
bjobs –r 显示正在运行的作业
bjobs –a 显示正在运行的和最近完成的作业
bjobs – p 显示等待运行的作业和等待原因
bjobs –s 显示正在挂起的作业和挂起的原因
bjobs -l 显示该作业的所有信息
bjobs -u all | sort 显示全部作业并排序
-
bjobs -UF <jobid>看PENDING REASONS, 如果显示“Job was suspended by the user while pending;”或者类似的信息,可以看是不是用户或者LSF administrator操作导致的。
-
也可能是其它限制强迫job变成了PSUSP,比如如果job启动的时候用户环境无法初始化,会导致job无法从PEND转为RUN状态,也会变成PSUSP。
bhist 显示最近完成作业或正在运行作业的历史情况
bhist <jobid>
bkill 删除不需要的作业
bkill <jobid>
bkill –r <jobid>
bkill -u all 0 清楚全部作业
bkill -u username 0,删除该用户下所有提交的并行任务
bkill -m hostid -u all 0 ,删除某台主机上的所有任务
bpeek 当作业正在运行时显示它的标准输出,监视作业运行
bpeek <jobid>
bqueues 显示队列信息
bqueues
bqueues –l <queue name>
在 LSF (Openlava) 系统中,作业可能处于下列的状态中:
¨ PEND (待定)– 作业在队列中等待调度与分派,可能的原因:1、资源不足,2、授权数量不足,3、作业槽可用数量满
¨ RUN (运行)– 作业已经被分派到节点机上,正在运行
¨ DONE (完成)– 作业已正常结束,正常退出值为 0
¨ EXIT (退出)– 作业已经结束,但退出值不是 0,可能的原因:1、脚本错误,2、运行中进程崩溃等
¨ PSUSP(待定挂起)– 作业在待定时被挂起 ,可能的原因
¨ USUSP(用户挂起)– 作业被用户指定挂起
¨ SSUSP(系统挂起)– 作业被 LSF 系统挂起
¨ POST_DONE(后处理完成)– 作业的后处理动作,成功完成
¨ POST_ERR(后处理出错)– 作业的后处理动作,出错
¨ UNKWN(不确定)– mbatchd 与执行节点机上的 sbatchd 失去联系,从而使作业状态不确定
¨ WAIT(等待)– 对于提交到 “块作业” 队列中的作业,作为 “块作业” 的成员所处于的等待状态
¨ ZOMBI(僵尸)– 作业成为僵尸是因为系统失去了与作业执行节点的联系
bhosts 显示各节点作业相关情况
bhosts <hostname>
Bhosts -w
lsload 显示各节点负载信息
lsload <hostname>
lsload -l
Lsload | sort
如果指定了lsload -l,则显示磁盘 I/O 速率在最后一分钟内呈指数平均,以每秒 KB 为单位。
[root@rd11 ~]# lsload -l
HOST_NAME status r15s r1m r15m ut pg io ls it tmp swp mem
rd11 ok 0.0 0.0 0.1 0% 0.0 0 4 6 41G 4096M 5982M
rd22 ok 0.0 0.0 0.0 0% 0.0 0 0 2e+08 41G 3992M 2484M
| r15s | 15 秒指数平均 CPU 运行队列长度。 |
| r1m | 1 分钟指数平均 CPU 运行队列长度。 |
| r15m | 15 分钟指数平均 CPU 运行队列长度。 |
| ut | CPU 利用率在最后一分钟内呈指数平均,介于 0 和 1 00%之间。 |
| pg | 内存分页率在最后一分钟内呈指数平均,以每秒页数为单位。 |
| ls | 当前登录用户数。 |
| it | 在 UNIX 上,主机的空闲时间(键盘未触及所有登录的会话),以分钟为单位。在 Windows 上,it 索引基于屏幕保护程序在特定主机上的活动时间。 |
| tmp | /tmp 中的可用空间量,以 MB 为单位。 |
| swp | 可用交换空间量。默认情况下,金额以 KB 为单位显示。该数量可能会以 MB 为单位显示,具体取决于实际的系统交换空间。 |
| mem | 可用 RAM 量。默认情况下,金额以 KB 为单位显示。该数量可能会以 MB 为单位显示,具体取决于实际的系统交换空 |
| io | 默认情况下,不显示 io。 |
lshosts处理各节点静态资源信息
lshosts <hostaname>
bsub
官方操作指导手册:
https://www.ibm.com/docs/en/spectrum-lsf/10.1.0?topic=reference-bsub
bsub -q <队列名> -m <机器名> -n <线程数> -o <标准输出文件> -e <标准错误输出文件> -J <作业名> <命令>
-q:指定队列名,如果不指定,默认使用 normal 队列
-m:指定主机名,可以仅指定一台服务器执行任务。不指定会默认调度到同一种架构的服务器;如果集群存在多种类型服务器,必须指定主机名才能在异构的服务器上执行
-n:指定并发量,一般用于多并发的Job
-o:可选参数,指定作业执行中的标准输出文件
-e:可选参数,指定作业执行中的标准错误输出文件
-J:可选参数,指定作业名,不指定默认为提交作业执行的命令名
-i:指定作业的输入文件
-Ip:提交一个交互式作业并开启一个伪终端,交互式任务时必选
-w ‘dependecy_expression’ , 提交作业前,指定操作。
操作有: done
ended, 如 –e “ended(aaaa*)” , 表示作业名中有aaaa的作业,完成之后才可以提交作业
exit
-W 限定作业运行时间
-K 提交作业,并且等待作业完成。当提交作业后,终端打印“waiting for dispath”。
当作业完成后,终端打印“job is finished”。作业没有完成,不能提交新的作业。
%J,可表示作业号
————————————————
#示例
bsub sleep 100 #随机选择节点单线程执行
bsub -m ctsh -n 5 test.sh #指定 ctsh 预定 5 个 CPU core 执行 test.sh
bsub -Ip vim testfile.txt #分配一个节点以 Interactive 方式打开 vim
1、输入完整参数提交————————————————
直接输入 bsub 完整参数,可以方便地提交单线程作业。 下面这条命令提交了一个需要一个 CPU 核运行的单线程作业:
$ bsub -n 1 -q cpu -o job.out ./myprog “-input data.txt”
主要参数说明如下:
• -n 指定所需的计算核心数。
• -q 指定作业运行的队列,在集群上可用的计算队列有 cpu、fat、gpu和 mic等。
• -o 指定作业运行信息的输出文件。
• ./myprog 是要提交运行的可执行文件,
• “-input data.txt”是传递给 myprog 的命令行参数。
当然,这种用法仅适用于简单的作业,更复杂的作业控制需要编写作业脚本,请参考下面“使用作业脚本提交”。
2、作业脚本提交————————————————
作业脚本是带有“bsub 格式”的纯文本文件。 作业脚本易于编辑和复用,是提交复杂作业的最佳形式。 下面是名为 job.script 的作业脚本的内容:
#BSUB -n 4
#BSUB -q cpu
#BSUB -o job.out
input file is data.txt
./mytest “-input data.txt”
其中以#BSUB 开头的行表示 bsub 作业参数,其他#开头的行为注释行,其他行为脚本运行内容。作业脚本的使用方法很简单,只需要把脚本内容通过标准输入重定向给 busb:
$ bsub < job.script
以上脚本等价于如下命令:
$ bsub -n 1 -q cpu -o job.out ./mytest “-input data.txt”
bsub 默认会调用/bin/sh 执行脚本内容,因此可以使用 Shell 编程脚本对作业参
数进行处理和控制。 下面这个作业脚本提交了一个需要 64核心的 MPI计算任务。在下面名为 64core.script 的作业脚本会由 LSF 使用 bash 解释运行,需要使用64 个核心,且要求每个节点提供 16 个计算核心。
64core.script
#BSUB -L /bin/bash
#BSUB -J HELLO_MPI
#BSUB -n 64
#BSUB -e %J.err
#BSUB -o %J.out
#BSUB -R “span[ptile=16]”
#BSUB -q cpu
MODULEPATH=/lustre/utility/modulefiles:$MODULEPATH
module purge
module load openmpi/gcc/1.6.5
mpirun ./mpihello
用户在命令行下用 bsub 提交作业:
$ bsub < 64core.script
关于 MPI 程序和作业脚本的详细例子,请参考《并行程序示例》中的内容。
3、交互提交 ————————————————
键入 bsub 回车后,可进入 bsub 交互环境输入作业参数和作业程序。 bsub 交互环境的主要有点是可以一次提交多个参数相同的作业。例如:
$ bsub
bsub> -n 1
bsub> -q cpu
bsub> -o job.out
bsub> PROG1
bsub> PROG2
bsub> PROG3
CTRL+d
等价于提交了 PROG1、PROG2 和 PROG3 三个作业程序:
$ bsub -n 1 -q cpu -o job.out PROG1
$ bsub -n 1 -q cpu -o job.out PROG2
$ bsub -n 1 -q cpu -o job.out PROG3
指定作业运行的节点
在作业脚本中可以使用#BSUB -R “select[hname=HOSTNAME]”指定作业运行的节点。譬如:
16core.script
#BSUB -L /bin/bash
#BSUB -J HELLO_MPI
#BSUB -n 16
#BSUB -e %J.err
#BSUB -o %J.out
#BSUB -R “span[ptile=16]”
#BSUB -R “select[hname=mic02]”
#BSUB -q cpu
MODULEPATH=/lustre/utility/modulefiles:$MODULEPATH
module purge
module load openmpi/gcc/1.6.5
mpirun ./mpihello
bsub -R “资源锁定”
主机选取(Selection)- select[selection_string]
MBD 选择最合适的执行主机。主机的选取依据主机选取字符串的值进行。主机选取字符串(select):
❖ 是由一系列的资源名称构建得到的一个逻辑表达式
❖ 指定了能被选择作为候选 execution 主机的 server 主机的特征
❖ 对每个主机都进行评估
❖ 当此表达式的值为“true”时,该主机被选择为候选 execution 主
eg:
bsub -R “select[swp>=300 && mem>500]” job1
提交作业至一个候选主机,要求该主机有至少 300 MB 的可用交换分区和至少 500 MB的可用内存。
资源排序(Ordering)- order[order_string]
用于对候选的 execution 主机根据资源值进行分类排序,使用资源排序字符串(order)实现:
order 资源排序
❖ 第一个指标为主分类指标,第二个指标为次分类指标,依此类推
❖ 主机根据指定的一个或多个指标按照从最好至最坏的顺序进行排序
❖ 当作业级别的和队列级别的该指标分别被定义时,作业级别的优先
❖ 默认的排序字符串为 order[r15s:pg]
eg:
bsub -R “select[type==any && swp>=300 && mem>500] order[mem]” job1
其中 order[mem]表示对候选的 execution 主机按照可用内存值从最高至最低进行排序
资源使用率(Usage)- rusage[rusage_string]
❖ 作业级别的资源要求:bsub -R
❖ 队列级别的资源要求:RES_REQ
集群中 slave 主机上的 Cube daemon 会定期将资源使用率信息上报给 master 主机;master 主机从所有 slave 主机上收集所有资源的使用率信息。 资源使用率字符串(rusage)用于指定 execution 主机上的资源预留。默认情况下,无资源预留。当运行交互式任务时可忽略。当作业级别的和队列级别的 rusage 均被定义时,作业的级别优先。
eg:
bsub -R “select[swap>=300 && mem>500] order[swap:mem] rusage[swap=300,mem=500]” job1
在被选取的主机上,为运行该作业预留 300 MB 的交换分区和 500 MB 的内存
通过rusage[mem=500]预留内存大于jobs使用内存时可避免SUSP情况
资源位置(Locality)- span[span_string]
用于指定并行作业的位置。 支持的选项: ❖ span[hosts=1]:代表分配给该作业的所有处理器必须在同一个 execution 主机上 ❖ span[ptile=n]:代表每个 execution 主机上都要分配给该作业多达 n 个处理器当此字符串(span)在作业级别和队列级别分别被定义时,作业级别的定义优先。
eg:
bsub -n 16 –R “select[ut<0.15] order[ut] span[hosts=1]” parallel_job1
用来完成该作业的所有处理器必须在同一个 execution 主机上。
bsub -n 16 –R “select[ut<0.15] order[ut] span[ptile=2]” parallel_job2
每个 execution 主机上,可以使用 2 个 CPU 来运行该作业,因此至少需要 8 个 execution主机用来完成该作业
Some other examples.
====
Job need 4 cpu slots, every slot need 100G memory (Total 4*100=400G memory). 任务属于项目test,需要4个cpu核,为每个核预占100G内存(内存默认按照cpu核分配,而不是按照job分配),总体预留400G内存。 bsub -P test -n 4 -R “rusage[mem=100000]” “COMMAND”
Job need 4 cpu slots, and the 4 slots must be on the same host. 任务属于项目test ,需要4个cpu核,且要求4个核在同一台机器上(在设置了“span[hosts=1]”的前提下,机器上总共剩余100G内存任务即可投递成功) bsub -P test -n 4 -R “span[hosts=1] rusage[mem=100000]” “COMMAND”
Submit job into pd queue, select the hosts who have 500G+ memory, 100G+ swap, 100G+ tmp. 任务属于项目test ,需要投递到pd队列,要求投递的机器剩余内存大于500G,剩余swap大于100G,剩余tmp空间大于100G。(select能够选择当前满足条件的机器,但是不能预占机器上的资源,用rusage预占资源) bsub -P test -q pd -R “select[mem>=500000 && swap>=100000 && tmp>=100000]” “COMMAND”
Submit job into pd queue, need 8 cpu slots, reserve 100G memory, 100G swap, select the hosts who have 100G+ tmp. 任务属于项目test ,需要投递到pd队列,需要8个cpu核,选择tmp空间大于100G的机器,预占100G内存和100Gswap。 bsub -P test -q pd -n 8 -R “rusage[mem=100000:swap=100000] select[tmp>=100000]” “COMMAND”
Submit job into pd queue, need >8 cpu slots, or sorts by CPU 提交任务需要按照cpu slots来提交任务 bsub -P test -q pd -R “rusage[mem=1024] select[slots>8]” “COMMAND” or bsub -P test -q pd -R “rusage[mem=1024] order[slots]” “COMMAND”
说明:
以上资源默认单位为MB
LSF管理员
LSF守护进程介绍
管理节点(Master)
mbatchd
管理批处理守护进程,运行在管理主机上。负责系统中作业的总体状态。接收作业提交和信息查询请求。管理队列中保存的作业。将作业分派到mbschd确定的主机上。
master lim
LIM运行在管理主机上。从集群中主机上运行的LIMs接收负载信息。将负载信息转发给mbatchd,后者将该信息转发给mbschd以支持调度决策。如果管理主机LIM不可用,管理候选主机上的LIM将自动接管。
pim
进程信息管理器(PIM)运行在每个服务器主机上。由LIM启动,它定期检查PIM并在PIM死亡时重新启动PIM。收集主机上运行的作业进程信息,如作业所使用的CPU、内存等,上报给sbatchd。
res
远程执行服务器(RES)运行在每个服务器主机上。接受远程执行请求,以提供清晰和安全的作业和任务远程执行。
sbatchd
运行在每一个主机上,包括管理主机,接收mbatchd运行任务的请求,并管理本地运行的任务,负责执行本地策略和维护主机上的作业状态。sbatchd会为每一个任务创建一个sbatchd的子进程,子进程运行在res的实例中,来创建每一个任务的执行环境,当任务完成之后子进程则退出。
mbschd
管理批调度程序守护程序,运行在管理主机上。与mbatchd一起工作。根据工作要求、策略和资源可用性做出调度决策并向mbatchd发送调度决策,mbatchd根据调度决策进行作业的分派。
Parent LiM
运行在管理主机的lim,从各个主机上运行的lim出收集各个主机的负载信息,并将负载信息转发给mbatchd,mabatchd会将这些信息转发给mbschd来调配调度策略,如果管理主机上的lim变成不可用,那么候选管理主机上的lim将会自动接替此lim的位置。
计算节点(Compute Hosts)
sbatchd
运行在每一个主机上,包括管理主机,接收mbatchd运行任务的请求,并管理本地运行的任务,负责执行本地策略和维护主机上的作业状态。sbatchd会为每一个任务创建一个sbatchd的子进程,子进程运行在res的实例中,来创建每一个任务的执行环境,当任务完成之后子进程则退出。
res
远程执行服务器(RES)运行在每个服务器主机上。接受远程执行请求,以提供清晰和安全的作业和任务远程执行。
lim
加载信息管理器(LIM)运行在每个服务器主机上。收集主机负载和配置信息,转发给管理主机上运行的管理主机LIM。报告lsload和显示的信息
pim
进程信息管理器(PIM)运行在每个服务器主机上。由LIM启动,它定期检查PIM并在PIM死亡时重新启动PIM。收集主机上运行的作业进程信息,如作业所使用的CPU、内存>
等,上报给sbatchd。
ELIM: External LIM (ELIM)是一个站点可定义的可执行文件,用于收集和跟踪自定义动态负载索引。ELIM可以是shell脚本或已编译的二进制程序,它返回您定义的动态资源的值。ELIM可执行文件必须命名为ELIM.anthing,并且位于LSF_SERVERDIR中定义的路径中。
LSF配置文件介绍
LSF配置是通过几个配置文件管理的,您可以使用这些配置文件修改集群状态。
-
LSF_CONFDIR/lsf.conf
-
LSF_CONFDIR/lsf.cluster.cluster_name
-
LSF_CONFDIR/lsf.shared
-
LSB_CONFDIR/cluster_name/configdir/lsb.queues 在初始化的安装过程中,将会产生这些配置文件,最初的配置是由初始化的install.config文件进行确定,安装完成之后,仍然可以修改这些配置文件来适配实际的应用环境。
配置文件的所有者属性
除了LSF_CONFDIR/lsf.conf是属于root以外,其他的配置文件的所有者都是LSF administrator,其他集群用户拥有只读权限。
lsf.conf
lsf.conf是最重要的lsf配置文件,里面包含配置文件、日志文件、库文件和其他全局配置的路径信息。lsf.conf的路径是由LSF_ENVDIR环境变量进行确定,如果lsf找不到这个文件,将不能正确的启动。 默认情况下,lsf将会检查由LSF_ENVDIR定义的参数信息,如果在LSF_ENVDIR定义的路径下没有找到lsf.conf,将会再到/etc/目录下进行寻找。
lsf.cluster.cluster_name
定义集群中所有主机的主机名称、主机类型(决定负载和计算中应用的CPU缩放系数)以及主机类型(操作系统及CPU架构),以及定义lsf administrator的名称,并指定一个集群的不通共享资源的路径。
lsf.shared
这个文件就像一个字典,定义了集群使用的所有关键字。您可以添加自己的关键字来指定资源或主机类型的名称。
lsb.queues
为一个集群定义工作负载队列及其参数。
lsf directories
以下的目录的所有这是lsf administrator,同时被其他集群成员可读。
以下的目录的所有者是root,同时被其他集群成员可读:
其他的配置文件目录可以在LSF_CONFIDIR/lsf.conf文件中进行配置。
LSF cluster configuration files
以下的目录的所有这是lsf administrator,同时被其他集群成员可读。
LSF批处理工作负载系统配置文件
LSF batch log files
Daemon log files
LSF 服务器守护进程日志存储在由lsf.conf文件定义的目录中。
LSF添加节点
一、关闭selinux
vim /etc/selinux/config
二、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
三、 挂载目录lsf相关目录
四、 确认解析
修改lsfmaster与当前主机的hosts,确保可以互相解析
五、修改配置文件
当前主机进入LSF配置文件目录:/tools/ibm/lsf/conf/
修改lsf.cluster.platform文件
复制之前的行,将名字修改为新主机名字(一定要与lsfmaster互相解析)
六、 重置LIM(在lsfmaster执行)
lsadmin reconfig
七、重启mbatchd(在lsfmaster执行)
badmin mbdrestart
八、设置节点lsf自动启动守护进程(在新主机执行)
/tools/ibm/lsf/10.1/install/hostsetup –top=”/tools/ibm/lsf/10.1″ –boot=”y”
九、在新主机上启动lsf(在新主机执行)
lsadmin limstartup
lsadmin resstartup
badmin hstartup
至此,新节点增加完毕
添加节点到queue
1、 进入节点配置目录:
cd /tools/ibm/lsf/conf/lsbatch/platform/configdir
2、 修改配置文件:lsb.queues 和lsb.hosts
3、 在对应queue内增加主机名即可
4、 重新配置queue信息
badmin reconfig
注意:此处执行后无效,请再执行
lsadmin reconfig
LSF队列(lsb.queue)的基本配置
1、功能介绍
LSF配置的核心是lsb.queues,也就是队列的配置,先看一个基本的队列设置
Begin Queue
QUEUE_NAME = normal 队列名称
FAIRSHARE = USER_SHARES[[default,1]] 竞争策略
UJOB_LIMIT = 48 每个用户最大可用slot的数目
RUNLIMIT = 168:0 job最长运行时间限制,单位为 小时:分钟
QJOB_LIMIT = 1500 queue中最大job运行数目限制
HOSTS = normal 队列中机器设置(此处normal为host组的名称)
DESCRIPTION = Default queue, for normal jobs. 队列描述
End Queue
2、lsb.queue参数
| 参数 | 参数名称 | 功能描述 |
| QUEUE_NAME | 队列名称 | 指定最多 59 个字符长的任何 ASCII 字符串。您可以使用字母、数字、下划线 (_) 或破折号 (-)。不能使用空格。您不能指定保留名称default. |
| FAIRSHARE | 队列竞争策略 | 用于定义用户新提交的job之间的竞争策略,示例中的设置意为,在queue负载全满的情况下,所有用户公平竞争,即无论每个用户PEND的job数目有多少,当有新的resource空余出来的时候,所有用户之间公平分配空闲resource。 |
| DESCRIPTION | 队列描述 | Default queue, for normal jobs. 队列描述,无实际意义 |
| INTERACTIVE=YES| NO| ONLY | 交互式队列 | 如果设置为 YES,则使队列接受交互式和非交互式批处理作业。如果设置为 NO,则导致队列拒绝交互式批处理作业。如果设置为 ONLY,则使队列接受交互式批处理作业并拒绝非交互式批处理作业。交互式批处理作业通过bsub -I提交,队列默认接受交互式和非交互式作业 |
| PRIORITY | 优先级 | 指定调度作业的相对队列优先级。较高的值表示相对于其他队列的作业调度优先级较高,默认优先级为1 |
| QJOB_LIMIT | 此队列中的作业可以使用的最大作业槽数。默认值是无限的,数值必须合理配置,太小容易造成queue中运行的job的数目过少,浪费资源,太大则容易造成用户可运行job数目太多而快速吃光资源,导致后提交任务的用户总是得不到资源而使job处于PEND的状态。 | |
| UJOB_LIMIT | 任何一个用户可用于此队列中作业的最大作业槽数。默认值是无限的 | |
| PJOB_LIMIT | 任何一个处理器上可用于此队列中作业的最大作业插槽数。默认值是无限的 | |
| HJOB_LIMIT | 主机最大作业数 | 此参数定义此队列可以在任何主机上使用的最大作业槽数。这个限制是为每个主机配置的,不管它可能有多少处理器。 |
| HOSTLIMIT_PER_JOB | 最大主机数 | 此参数定义此队列中的作业可以使用的最大主机数。LSF 在调度的分配阶段验证主机限制。如果并行作业请求的主机数量超过此限制,并且LSF无法满足最小请求槽数,则并行作业将挂起。 |
| CPULIMIT | 限制作业可以使用的总CPU时间。此参数对于防止失控作业或占用过多资源的作业很有用。当整个作业的总CPU时间达到限制时,将向属于该作业的所有进程发送SIGXCPU信号。如果作业没有SIGXCPU的信号处理程序,作业将立即终止。如果应用程序处理、阻止或忽略了SIGXCPU信号,则在宽限期到期后,LSF 会向作业发送 SIGINT、SIGTERM和SIGKILL以将其终止 | |
| MEMLIMIT | 设置此参数可为属于此队列中的作业的所有进程设置每个进程的硬进程驻留集大小限制(以 KB 为单位) | |
| CPU_FREQUENCY | 所有提交到队列的作业都需要指定的 CPU 频率。值是带单位(GHz、MHz 或 KHz)的正浮点数。如果未设置单位,则默认为 GHz。您还可以使用bsub -freq来设置此值。提交值覆盖应用程序配置文件值,应用程序配置文件值覆盖队列值。 | |
| FILELIMIT | 指定此队列中所有作业进程的每个进程文件大小限制 | |
| DATALIMIT | 设置此参数可为属于此队列中作业的所有进程设置每个进程数据段大小限制(以 KB 为单位) | |
| STACKLIMIT | ||
| THREADLIMIT | 限制可以成为作业一部分的并发线程数。超出限制会导致作业终止。 | |
| TASKLIMIT | 指定可以分配给作业的最大任务数 | |
| CORELIMIT | 指定此参数可为属于此队列中作业的所有进程设置每个进程的硬核文件大小限制(以 KB 为单位),默认无限 | |
| PROCLIMIT | #队列可以接受的并行作业的处理器限制(并行限制)。如果提交的作业请求的处理器数量超过此限制,则该作业将被拒绝。如果未定义,则默认值为无穷大。 | |
| SWAPLIMIT | #作业中所有进程的最大虚拟内存,并以KB为单位指定。当达到此限制时,SIGQUIT被发送到作业,然后依次是SIGINT、SIGTERM和SIGKILL | |
| PROCESSLIMIT | #指定可以作为作业一部分的并发进程数。默认情况下,如果指定了默认进程限制,则在达到默认进程限制时,没有作业级进程限制的提交到队列的作业将被终止。如果您仅指定一个限制,则它是最大或硬性进程限制。如果指定两个限制,第一个是默认或软进程限制,第二个是最大进程限制。 | |
| USERS | #限制可以将作业提交到此队列的用户(默认为“所有用户”)。 | |
| HOSTS | #限制提交到此队列的作业可以在哪些主机上执行,部分可以直接定义host的名字列标,也可以仅表示host group name,然后在lsb.hosts中定义host group name对应的具体的host name,这样配置更加灵活。示例中采用后者。 | |
| PRE_EXEC | #在执行主机上运行从该队列调度的作业之前执行的命令。它在作业的用户ID下执行,标准输入、输出和错误重定向到/dev/null | |
| POST_EXEC | #在从该队列中调度的作业在执行主机上完成运行后执行的命令。如果PRE_EXEC命令以0退出状态退出,但作业的执行环境设置失败,也会运行该命令。它在作业的用户ID下执行,标准输入、输出和错误重定向到/dev/null | |
| RES_REQ | #一个资源需求字符串,指定将作业分派到主机的条件。还可以在此字符串中指定资源保留和位 | |
| STOP_COND | #一个资源需求字符串,指定停止正在运行的作业的条件。停止作业时,只考虑字符串的“select”部分 | |
| RESUME_COND | #一个资源需求字符串,指定恢复挂起作业的条件。恢复已停止的作业时,只考虑字符串的“选择”部分 | |
| FAIRSHARE | #FAIRSHARE策略用于调度队列中的作业。默认情况下,作业是基于FIFO进行调度的。fairshare调度程序将队列槽的特定部分分配给每个参与者用户。关键字USER_SHARES用于指定每个用户的共享。用户共享的值由一个或多个[用户名,共享]对组成 | |
| HOSTS_SHARES | #用于控制一台主机的多少个CPU内核应该绑定到特定队列中的作业。HOSTS_SHARES的值由一个或多个[hostname,share]|[hostgroup,share]|[all,share]对组成 | |
3、配置策略
按照job RUNLIMIT(运行时间限制)的区分,建议分出3个队列,short/normal/long。short一般用于运行短时就能完成的job,RUNLIMIT很短(比如一天);normal属于默认队列,RUNLIMIT中等(比如一周);long属于运行超长时间的job(至少一个月,也可以设成更长甚至无时间限制),为了防着用户滥用long队列,其UJOB_LIMIT需要设置的较小。
按照机器资源也可以分出一些特殊队列,比如有些EDA工具需要大量的cpu,但是对memory不敏感,比如regression,那么可以把cpu核数很高的机器分到一个单独队列。有些EDA工具需要极大的内存,但是对cpu数目要求不高,比如后端工具,可以把memory极大地机器分到一个队列。
按照IC设计的flow也可以分出一些特殊队列。不同IC设计流程所需要的运算资源也不一样。比如验证的regression需要极大量的slots,但是memory需求不高,而且job的运算时间一般较短,所以可以把多cpu核数的机器单列一个regression的队列;比如后端的工具需要slot不多,但是对memory需求极大,而且运行时间往往也很长,可以把大内存机器单列一个pd的队列。
队列设置的整体思路是:
-
为提高机器利用率的话,队列中尽量采用共享机器。
-
特殊应用,尤其是对资源需求比较大的,为保证效率一般设置队列采用专有机器。
-
如果队列需要接收job的时候必须有运算资源,不得不预留一部分专有机器,但是这样有可能会造成一定程度的资源浪费,所以专有机器的数量要控制到合适范围。
-
尽量要预留一部分机动机器,以防备紧急任务没有资源可以调用。
-
opelnava队列的调整策略是一个动态的过程,需要根据IC设计运算需求动态调整。
4、配置举例
例1:LSF 指定进程提交到指定 QUEUES 中
在LSF中,我们经常会遇到某些应用在提交时必须提交到指定的queues 中去运行的情况。
如遇到这种需求,我们需要对进程进行判断,然后将进程扔到配置好的 queues 中即可。
操作分 3 步。
4.1、配置 esub,开启此项功能
配置 ****/lsf/conf/lsf.conf,添加以下行:
LSB_ESUB_METHOD=check
LSB_SUB_COMMANDNAME=Y
4.2、配置 esub 相关文件
建立配置文件:****/linux2.6-glibc2.3-x86_64/etc/esub.check。
编辑 esub.ckeck 文件
#!/bin/bash.$LSB_SUB_PARM_FILEexec 1>&2echo $LSB_SUB_COMMAND_LINE|grep 进程名 >/dev/nullif [ $? -eq 0 ];thenecho redierct job to queue: 指定的queuesecho LSB_SUB_QUEUE=\”指定的queues\”>> $LSB_SUB_MODIFY_FILEfiexit 0
3、建立专用 queues 接收提交的任务
在 ****/lsb.queues 中建立新队列:
Begin Queue
QUEUE_NAME = 队列名 //队列名
PRIORITY = 40 //队列优先级
RERUNNABLE = Y //RERUNNABLE
UJOB_LIMIT = 40 //每用户可提交作业数量
#RUN_WINDOW = 20:00-8:30
#USERS = xxxx xxxx //指定用户可提交,用户名 以空格分隔
#HOSTS = xxxx xxxx xxxx xxxx xxxx //队列中包含哪些服务器,服务器名,以空格分隔
DESCRIPTION = xxxx queues //队列描述
End Queue
重启,使配置生效
lsadmin reconfig
badmin reconfig
badmin mbdrestart
badmin hrestart
5、例2:LSF 指定job提交到指定QUEUES中
5.1 首先配置more lsb.queues,在队列里新增自定义队列,例如我加入一个名为ncc的队列
Begin Queue
QUEUE_NAME = ncc
PRIORITY = 30
NICE = 10
HOSTS = nccs
INTERACTIVE = ONLY
UJOB_LIMIT = 8
DESCRIPTION = for interactive jobs
End Queue
5.2 在lsb.hosts配置内将队列与指定服务器关联
Begin HostGroup
GROUP_NAME GROUP_MEMBER # Key words
batcs (rd3 rd5 rd6 rd7 rd8 rd9)
intcs (rd3 rd5 rd6 rd7 rd8 rd9)
nccs (rd4)
gpus (rd9)
End HostGroup
重启,使配置生效
lsadmin reconfig
badmin reconfig
badmin mbdrestart
badmin hrestart
5.3 在.cshrc内加入别名配置
alias bncc ‘bsub -Ip -q ncc’
bncc virtuoso
LSF队列调度策略调整-RES_REQ
工作背景:
集群中所有队里再使用过程中,频繁出现mem使用不均衡情况从而导致部分机器的jobs 变成SSUP状态;
状态 描述
PEND 作业在队列中等待被调度和分发。
RUN 作业已被分发至某个主机且正在执行。
DONE 作业已正常执行完成(退出码为 0)。
PSUSP 原 PEND 状态的作业,被该作业的提交者或管理员挂起。
USUSP 作业在被分发后,作业的提交者或管理员将其挂起。
SSUSP 作业在被分发后,系统将其挂起。
EXIT 作业非正常终止(退出码非 0)
————————————————
出现问题原因:
1)用户再提交任务过程中rusage预留mem资源不规范,mem值过小或者没有设置rusage
2)根据公司情况,集群内调度策略不合适,内存资源使用不规范,默认调度策略为:默认的排序字符串为 order[r15s:pg]
问题解决思路:
1)设置默认mem预留策略
2)调整集群内队列的调度策略用内存来优先调度,即选择用mem作为调度策略
负载信息中各项的含义如下:
❖ r15s:15 秒指数平均 CPU 运行队列长度。
❖ r1m:1 分钟指数平均 CPU 运行队列长度。
❖ r15m:15 分钟指数平均 CPU 运行队列长度。
❖ ut:最近 1 分钟内的 CPU 指数平均利用率,取值范围为 0 至 1。
❖ io:默认关闭。当-l 选项指定时,显示最近 1 分钟内的指数平均磁盘 I/O 速率,以 KB/秒计算。
❖ pg:最近 1 分钟内的指数平均内存分页率,以页数/秒计算。
❖ ls:当前登录的用户的个数。
❖ it:主机的空闲时间(即所有已登录的会话中未发生键盘操作),以分钟计算。
❖ tmp:/tmp 下可用空间的大小(MB)。
❖ swp:可用的交换空间的大小。默认情况下,该值以 MB 为单位显示。
❖ mem:可用的内存量。默认情况下,该值以 MB 为单位显示
增加队列参数如下:
RESRSV_LIMIT = [mem=0,8000000]
RES_REQ = rusage[mem=10000] order[mem] #rusage10G mem Schedule first
注意事项:
1)RESRSV_LIMIT 必须限制,否则当用户设置rusage[mem=100000] 当设置大于默认的10000时,会无法提交jobs ,报错如下:
2)lsf 队列中仅仅识别一个RES_REQ参数,必须写成一行才生效
LSF限制作业最大内存的几种方法
为什么需要限制作业的最大内存?
不少LSF用户都可能碰到这样的情况:提交到LSF的作业或程序,有时会出现内存泄漏,或者有意想不到的内存分配情况,使得其它进程因无法分配到足够的内存而出现异常。尽管有的客户也采用了bsub -R “rusage[mem=$number]”来为作业预留内存,以保证计算节点有足够的内存来启动和运行作业,但是用户往往对作业程序使用的内存预估不足,结果作业实际所耗内存远远大于预留内存,导致计算节点运行缓慢,甚至对系统造成影响,引发宕机。
站在一个普通的LSF用户角度,如果能通过LSF控制作业所能使用的内存大小,那么就算作业进程有内存泄漏也不会对系统造成影响(可以设置内存使用上限,当到达这个上限值后LSF自动将作业杀掉)。
站在一个LSF系统管理员的角度,如果能通过LSF限制作业所能使用的内存量,不管用户对自己的作业使用内存评估是否准确,即使作业使用内存大大超过了预留内存,都能将它们对系统的影响降到最低,从而保证整个系统的稳定性。
那么LSF内部是如何实现对作业的内存限制呢?
在不使用Linux cgroup的情况下(后文介绍Linux cgroup),LSF有两种强制内存限制的方法:
-
由操作系统强制执行每个进程的内存限制。在这种情况下,LSF将配置的内存限制传递给操作系统,由操作系统通过setrlimit()系统调用来进行内存限制。
-
由LSF强制执行每个作业的内存限制。LSF获取作业所有进程消耗的内存之和,以确定作业是否已达到所指定的内存限制。当作业所有进程的总内存超过内存限制时,LSF会依次发送以下信号来终止作业进程:SIGINT、SIGTERM和SIGKILL。
LSF内存限制如何配置?
LSF有关内存限制的设置,有两个参数:
-
LSB_JOB_MEMLIMIT,该参数用来设置内存限制是由操作系统强制执行还是由LSF强制执行。当LSB_JOB_MEMLIMIT设为Y时,由LSF强制执行(作业级);当LSB_JOB_MEMLIMIT设为N或未定义时,由操作系统强制执行(进程级)。
-
LSB_MEMLIMIT_ENFORCE,使能这个参数可以同时启用LSF强制执行(作业级)和操作系统强制执行(进程级)。
这两个参数的关系说明如下:
| 参数名 | 参数值 | LSF强制执行(作业级) | 操作系统强制执行(进程级) |
| LSB_JOB_MEMLIMIT | Y|y | Enabled | Disabled |
| N|n 或未定义 | Disabled | Enabled | |
| LSB_MEMLIMIT_ENFORCE | Y|y | Enabled | Enabled |
基于Linux cgroup的内存限制
LSF还支持通过Linux cgroup来进行作业的内存限制。如果想通过Linux cgroup进行内存强制,需要在lsf.conf文件中配置:
-
LSB_RESOURCE_ENFORCE=”memory”
-
LSF_PROCESS_TRACKING = Y
-
LSF_LINUX_CGROUP_ACCT = Y
配置上述参数后,如果作业进程占用的内存超过了限制,Linux cgroup内存子系统会自动终止该作业。
LSF内存限制应用举例LSF可以通过在作业级别(bsub的-M选项)、队列级别(在lsb.queues里设置MEMLIMIT参数)或者应用级别(在lsb.applications里设置MEMLIMIT参数)设置内存限制。下面我们以作业级别为例进行介绍。示例1:提交一个作业,指定内存限制为100K。
$ bsub -M 100 sleep 1h
Job <20894> is submitted to default queue <normal>.
说明:在默认情况下,LSF资源限制大小单位为KB,在lsf.conf可以配置LSF_UNIT_FOR_LIMITS参数来设置其它单位(MB、GB、TB、PB或EB)。通过bjobs可以查看作业指定的内存限制(MEMLIMIT输出):
$ bjobs -l
Job <20894>, User <usr1>, Project <default>
, Status <RUN>, Queue <normal>, Command <sleep 1h>, Share
group charged </usr1>
Mon Nov 1 18:01:41: Submitted from host <host1>, CWD </tmp>;
Mon Nov 1 18:01:41: Started 1 Task(s) on Host(s) <host2>, Allocated 1 Slot(s) on Host(s) <host2>, Execution Home </home/usr1>, Exe
cution CWD </tmp>;
Mon Nov 1 18:01:48: Resource usage collected.
MEM: 1 Mbytes; SWAP: 1 Mbytes; NTHREAD: 4
PGID: 17883; PIDs: 17883 15945 15947
MEMLIMIT
100 K
MEMORY USAGE:
MAX MEM: 2 Mbytes; AVG MEM: 2 Mbytes
……
由于我们目前并没有启用前述LSF参数,默认情况下LSF将通过操作系统来进行强制内存限制。操作系统会给作业进程设置最大驻留内存限制(max resident set)。通过刚才的bjobs输出,我们知道作业进程PID是17883,进而可以通过下面这条命令查看该进程的操作系统限制:
$ cat /proc/17883/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size unlimited unlimited bytes
Max core file size unlimited unlimited bytes
Max resident set 102400 unlimited bytes
Max processes 513391 513391 processes
Max open files 7777 7777 files
Max locked memory 65536 65536 bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 513391 513391 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
可以发现,上面输出中的Max resident set值是102400,即100 KB,与我们提交作业时bsub -M指定的值一致。值得注意的是,操作系统内存强制通常允许进程最终运行到完成,换句话说,这种方式并不能确保作业内存不超过预设值,因此上面这个例子的作业可以正常完成。接下来,我们通过LSF参数来设置更严格的内存限制。
示例2:在lsf.conf文件中配置LSB_JOB_MEMLIMIT = y,执行badmin hrestart all使其生效,查看生效后的配置命令如下:
$ badmin showconf sbd | grep LIMIT
LSB_JOB_MEMLIMIT = y
我们再次提交相同作业,仍然指定内存限制为100K。
$ bsub -M 100 sleep 1h
Job <20895> is submitted to default queue <normal>.
这个作业会因为内存超限而被LSF强制杀掉:作业exit,bhist有如下输出:TERM_MEMLIMIT: job killed after reaching LSF memory usage limit
$ bhist -l 20895
Job <20895>, User <usr1>, Project <default>, Command <sleep 1h>
Mon Nov 1 18:03:16: Submitted from host <host1>, to Queue <normal>, CWD </tmp>;
Mon Nov 1 18:03:17: Dispatched 1 Task(s) on Host(s) <host2>, Allocated 1 Slot (s) on Host(s) <host2>, Effective RES_REQ <select[type ==local] order[r15s:pg] >;
Mon Nov 1 18:03:17: Starting (Pid 17720);
Mon Nov 1 18:03:17: Running with execution home </home/usr1>, Execution CWD </tmp>, Execution Pid <17720>;
Mon Nov 1 18:03:21: Exited with exit code 130. The CPU time used is 0.0 seconds;
Mon Nov 1 18:03:21: Completed <exit>; TERM_MEMLIMIT: job killed after reaching LSF memory usage limit;
MEMLIMIT
100 K
MEMORY USAGE:
MAX MEM: 2 Mbytes; AVG MEM: 2 Mbytes
在lsf.conf中配置LSB_MEMLIMIT_ENFORCE = Y,也可以达到同样的效果,这里不再赘述。
我们再来看一个Linux cgroup的例子。
示例3:基于Linux cgroup内存子系统的内存限制。按照前面介绍的方法配置后,可以通过如下命令查看参数:
$ badmin showconf sbd | egrep “LSB_RESOURCE_ENFORCE | LSF_PROCESS_TRACKING | LSF_LINUX_CGROUP_ACCT”
LSB_RESOURCE_ENFORCE = memory
LSF_PROCESS_TRACKING = Y
LSF_LINUX_CGROUP_ACCT = Y
我们提交一个吃内存的程序,并指定内存限制为100M:
$ bsub -M 100M ./eatmem_perhost
Job <21102> is submitted to default queue <normal>.
启用Linux cgroup后,可以在系统的/sys/fs/cgroup/memory/lsf目录树下查看每个作业的内存限制。这是我们刚提交的这个作业的cgroup目录,内存限制值会被记录到memory.limit_in_bytes文件里:
$ ls /sys/fs/cgroup/memory/lsf/lsf10/job.21103.6077.1635835590/
memory.failcnt memory.kmem.tcp.failcnt memory.max_usage_in_bytes memory.numa_stat memory.usage_in_bytes
memory.force_empty memory.kmem.tcp.limit_in_bytes memory.memsw.failcnt memory.oom_control memory.use_hierarchy
memory.kmem.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.limit_in_bytes memory.pressure_level
memory.kmem.limit_in_bytes memory.kmem.tcp.usage_in_bytes memory.memsw.max_usage_in_bytes memory.soft_limit_in_bytes
memory.kmem.max_usage_in_bytes memory.kmem.usage_in_bytes memory.memsw.usage_in_bytes memory.stat
memory.kmem.slabinfo memory.limit_in_bytes memory.move_charge_at_immigrate memory.swappiness
$ cat /sys/fs/cgroup/memory/lsf/lsf10/job.21103.6077.1635835590/memory.limit_in_bytes
104857600
可以看到,memory.limit_in_bytes记录的值是104857600,即100M。
该作业运行一段时间后,由于不断占用内存,最终达到预设的100M内存限制,自动被Linux cgroup强制杀掉,bjobs和bhist会输出相应信息:
$ bjobs -l 21103
Job <21103>, User <usr1>, Project <default>,
Status <EXIT>, Queue <normal>, Command <./eatmem_perhost
105 10 10>, Share group charged </usr1>
Tue Nov 2 14:46:30: Submitted from host <host1>, CWD </tmp>;
Tue Nov 2 14:46:30: Started 1 Task(s) on Host(s) <host2>, Allocated 1 Slot(s)on Host(s) <host2>, Execution Home </home/usr1>, Exe
cution CWD </tmp>;
Tue Nov 2 14:46:31: Exited with exit code 137. The CPU time used is 0.1 second
s.
Tue Nov 2 14:46:31: Completed <exit>; TERM_MEMLIMIT: job killed after reaching LSF memory usage limit.
MEMLIMIT
102400 K
MEMORY USAGE:
MAX MEM: 100 Mbytes; AVG MEM: 33 Mbytes
$ bhist -l 21103
Job <21103>, User <usr1>, Project <default>, Command <./eatmem_perhost 105 10 10>
Tue Nov 2 14:46:30: Submitted from host <host1>, to Queue <normal>, CWD </tmp>;
Tue Nov 2 14:46:30: Dispatched 1 Task(s) on Host(s) <host2>, Allocated 1 Slot(s) on Host(s) <host2>, Effective RES_REQ <select[type ==local] order[r15s:pg] >;
Tue Nov 2 14:46:30: Starting (Pid 6071);
Tue Nov 2 14:46:30: Running with execution home </home/usr1>, Execution CWD </tmp>, Execution Pid <6071>;
Tue Nov 2 14:46:31: Exited with exit code 137. The CPU time used is 0.1 second
s;
Tue Nov 2 14:46:31: Completed <exit>; TERM_MEMLIMIT: job killed after reaching LSF memory usage limit;
MEMLIMIT
102400 K
MEMORY USAGE:
MAX MEM: 100 Mbytes; AVG MEM: 33 Mbytes
Summary of time in seconds spent in various states by Tue Nov 2 14:46:31
PEND PSUSP RUN USUSP SSUSP UNKWN TOTAL
0 0 1 0 0 0 1
上面3个示例表明,LSF可以在作业达到内存限制时杀掉作业,从而避免作业因占用内存过大而导致的OOM和宕机问题。配合之前介绍的bsub -R “rusage[mem=xxx]”、loadSched/loadStop等设置,可以实现比较好的内存控制效果。
LSF loadSched和loadStop功能防止计算节点内存溢出导致宕机
很多LSF用户都曾经遇到过这样的问题:某些作业运行时占用了大量内存,导致计算节点运行缓慢,甚至引发OOM(Out-Of-Memory)和系统宕机。
LSF在作业调度时,会根据作业指定的内存需求(bsub -R “rusage[mem=…]”)进行节点选择,并进行内部记录,将执行节点的可用内存记为减掉rusage预留内存之后的值。LSF调度下一个作业时,会根据该节点新的内存值,决定是否分配作业到该节点执行。
理论上,只要每个作业都指定rusage参数,并且作业实际占用内存都不超过rusage指定值,就应该不会发生内存OOM的情况。但在实际中,用户往往不能准确估算作业需要的最大内存,因此指定的rusage常常不准确。用户甚至可能不指定rusage参数。还有些用户通过bsub提交一个gnome-terminal作业来启动一个终端,再在这个终端里直接运行应用程序,绕开了LSF。这些情况都会导致LSF无法控制和预测作业资源消耗,在极端情况下,就会发生OOM和系统宕机。
提交作业时指定rusage可以在一定程度上避免OOM的发生,如果结合LSF的memory limit设置(后面专题介绍),则可以进一步降低OOM的概率,但是还不能彻底解决这个问题,其主要原因在于很难做到让全部作业都指定rusage,并且指定的预留内存一定小于实际占用内存。
LSF为我们提供了一种机制,可以对计算节点的loadSched和loadStop进行设置,这样能够大大降低OOM和系统宕机风险。本文介绍有关设置,并通过示例进行讲解。
配置介绍
在lsb.hosts里增加一列,指定负载指标的loadSched和loadStop阈值。例如:为某计算节点设置其mem负载的loadSched/loadStop配置为5120/2048,生效后有如下行为:
• 当计算节点的可用内存低于5120MB时,LSF将该计算节点关闭(bhosts将显示该节点状态为closed_Busy),阻止新作业分配到这个计算节点上。
• 当计算节点的内存低于2048MB时,LSF将该节点上运行的作业逐步挂起(bjobs将显示作业状态为SSUSP),挂起策略是:
• 先挂起低优先级队列的作业,再挂起高优先级队列的作业,同一个队列则挂起后运行的作业;
• 最终保留一个作业运行,不会全部挂起。
• 当计算节点可用内存恢复高于2048MB时,LSF逐步恢复挂起的作业。
• 当计算节点可用内存恢复高于5120MB时,LSF将该计算节点重新open。
示例讲解
在lsb.hosts文件里增加mem一列,并为host2设置mem loadSched/loadStop为5120/2048:
Begin HostHOST_NAME MXJ r1m pg ls mem tmp DISPATCH_WINDOW AFFINITY # Keywordshost2 ! () () () (5120/2048) () () (Y) # Exampledefault ! () () () () () () (Y) # ExampleEnd Host
解释:
1. 在HOST_NAME这一行添加”mem”字段;
2. 如果不想为某些节点添加mem loadSched/loadStop,则将其mem列设置成();
3. 也可以将mem设置成(5120/),即只设置mem loadSched,不设置loadStop,计算节点可用内存低于5120MB时,LSF只关闭计算节点不接受新作业,但是运行的作业不会挂起。
我们来观察作业。提交一些消耗内存的作业,当计算节点内存低于loadStop时,部分作业挂起(作业7441和7442):
$ bjobsJOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME7440 user1 RUN normal host1 host2 *eatmem 20 Oct 15 13:377441 user1 SSUSP normal host1 host2 *eatmem 20 Oct 15 13:377442 user1 SSUSP normal host1 host2 *eatmem 20 Oct 15 13:377443 user1 PEND normal host1 *eatmem 20 Oct 15 13:377444 user1 PEND normal host1 *eatmem 20 Oct 15 13:37
再来观察计算节点:
$ bhosts -l host2HOST host2STATUS CPUF JL/U MAX NJOBS RUN SSUSP USUSP RSV DISPATCH_WINDOWclosed_Busy 116.10 – 8 3 1 2 0 0 –
CURRENT LOAD USED FOR SCHEDULING: r15s r1m r15m ut pg io ls it tmp swp mem slots Total 0.0 0.0 0.0 0% 0.0 2 0 26 40G 5.9G *1.2G 5 Reserved 0.0 0.0 0.0 0% 0.0 0 0 0 0M 0M 0M –
LOAD THRESHOLD USED FOR SCHEDULING: r15s r1m r15m ut pg io ls it tmp swp mem loadSched – – – – – – – – – – *5G loadStop – – – – – – – – – – *2G
从上述结果可以看到:
• host2这个节点的mem loadSched/loadStop配置为5G/2G;
• 当前host2可用内存还有1.2G,低于配置的loadSched值(5G),计算节点的状态变为closed_Busy状态,LSF不再向这个计算节点分配新作业;
• host2可用内存1.2G,低于配置的loadStop值(2G),LSF自动将作业7441和7442挂起,变成SSUSP状态,只保留作业7440正常运行;
• 当作业7440结束后,如果可用内存回到loadStop值(2G)以上时,LSF将恢复7441和7442作业执行;
• 当host2可用内存恢复到loadSched值(5G)以上时,LSF会重新open这台host,接受作业调度。
以上我们介绍了loadSched/loadStop的基本用法,在实际使用的过程中可能会遇到各种具体问题,例如:
• 这里配置的loadSched/loadStop并不局限于mem(内存),也可以是ut(CPU利用率)等其它资源;
• 具体应用中还要考虑资源的性质,比如内存在作业挂起后并不释放,但CPU是释放的。所以对作业的处理方法也不尽相同。对于不释放的资源,很多用户会将挂起的作业自动杀掉或rerun,以免计算节点因为不能恢复高于loadSched值而造成计算节点停用。
LSF管理员-统计lsf队列里内存占用前10的作业
bjobs -u all -o “jobid user:10 exec_host max_mem” | grep Gbytes | sort -k4 -rn | head -10
LSF管理员-reconfig功能生效命令
当你修改了LSF的配置文件内容,你必须告诉LSF重新读取这些文件并更新相应的配置。请使用下面的命令来重新配置集群:
lsadmin reconfig
badmin reconfig
badmin mbdrestart
具体使用哪个命令要依据你对哪个文件进行了修改,你可以使用下表来快速查找。
配置之前也可以用badmin ckconfig检查最新更改的配置有没有问题
| 修改内容 | 命令 | 作用 |
| hosts | badmin reconfig | 重新载入配置文件; |
| license.dat | lsadmin reconfig 和badmin mbdrestart | 重启LIM, 重新载入配置文件,并重启mbatchd。 |
| lsb.applications | badmin reconfig | 重新载入配置文件;待发的作用会使用新的应用轮廓定义,而运行中的作业不会受到影响。 |
| lsb.hosts | badmin reconfig | 重新载入配置文件; |
| lsb.modules | badmin reconfig | 重新载入配置文件; |
| lsb.nqsmaps | badmin reconfig | 重新载入配置文件; |
| lsb.params | badmin reconfig | 重新载入配置文件; |
| lsb.queues | badmin reconfig | 重新载入配置文件; |
| lsb.resources | badmin reconfig | 重新载入配置文件; |
| lsb.serviceclasses | badmin reconfig | 重新载入配置文件; |
| lsb.users | badmin reconfig | 重新载入配置文件; |
| lsf.cluster.cluster_name | lsadmin reconfig 和badmin mbdrestart | 重启LIM, 重新载入配置文件,并重启rmbatchd。 |
| lsf.conf | lsadmin reconfig 和badmin mbdrestart | 重启LIM, 重新载入配置文件,并重启rmbatchd。 |
| lsf.licensescheduler | bladmin reconfig lsadmin reconfig badmin mbdrestart | 重设bld, 重设LIM, 重新载入配置文件,并重启r mbatchd。 |
| lsf.shared | lsadmin reconfig 和badmin mbdrestart | 重启LIM, 重新载入配置文件,并重启rmbatchd。 |
| lsf.sudoers | badmin reconfig | 重新载入配置文件; |
| lsf.task | lsadmin reconfig 和 badmin reconfig | 重启LIM, 重新载入配置文件。 |
使用lsadmin和badmin命令,重新设定集群
要使得配置修改的生效,请使用如下这个方法来重设集群。
1 使用root用户身份或是LSF管理员的身份,登录到节点。
2 运行lsadmin reconfig来重设LIM。
lsadmin reconfig
这个lsadmin reconfig命令会检查配置错误。如果配置没有错误,那么LSF会提示你选择,只重启候选主节点还是重启所有的节点上的LIM。如果配置中有重大的错误,那么重设过程会被中止。
3 运行badmin reconfig来重设mbatchd:
badmin reconfig
这个badmin reconfig命令会检查配置错误。如果配置中有重大的错误,那么重设过程会被中止。
通过重新启动mbatchd来重设整个集群
使用这个方法来重设集群,能够重载并恢复集群的运行状态。
1 运行badmin mbdrestart来重启mbatchd:
badmin mbdrestart
这个badmin reconfig命令会检查配置错误。如果配置没有重大错误,那么LSF会提示你确认重启mbatchd,如果配置中有重大的错误,那么这个命令就会被中止,不做任何动作。
注意:如果lsb.events 文件很大,或当前有很多作业在运行,那么重启mbatchd则会使用相当多的时间,而此时mbatchd是不接收服务请求的。
检查配置错误
1 运行 lsadmin ckconfig –v
2 运行 badmin ckconfig –v
这些命令会报告所有的错误到你的终端上。
重设集群是如何影响软件许可的
如果许可证服务器关闭了,那么LSF可以继续工作一段时间,直到LSF试图更新许可。
重设会使LSF更新许可。如果没有许可服务器可用,LSF不会重新设置集群,因为那样会使整个集群失去许可,导致所有工作停止。
如果你有多个许可服务器,如果LSF能够联系到其中至少一个许可服务器,那么重设过程就会继续,在这种情况下,LSF会失去那些保存在宕机的许可服务器上的许可,所以LSF在重设后可能会拥有更少的许可数量。
LSF操作指导整理