在LSF中,可以通过将作业拆分为多个子任务来实现并行计算。这种方法可以加速作业的运行,并最大程度地利用集群中的计算资源。
以下是在LSF中提交作业分多个子任务的一般步骤:
1. 编写作业脚本:编写一个能够将作业分成多个子任务的脚本。例如,您可以使用Bash for循环来迭代作业的不同部分,并将每个部分作为一个独立的子任务提交给LSF。 例如,以下是一个示例Bash脚本,用于将作业分成4个子任务: #!/bin/bash # Define the number of subtasks num_subtasks=4 # Iterate through the subtasks for ((i=1; i<=num_subtasks; i++)) do # Submit the subtask to LSF bsub -J my_job_$i -o my_job_$i.out -e my_job_$i.err my_job_subtask.sh $i done “` 在这个例子中,脚本将作业分成4个子任务,每个子任务都使用`bsub`命令提交到LSF中。每个子任务都使用不同的Job名称(例如“my_job_1”、“my_job_2”等),并将输出和错误日志文件分别写入不同的文件中。
2. 编写子任务脚本:编写一个脚本,用于执行每个子任务的实际计算。这个脚本应该可以接受命令行参数,并使用这些参数来指定该子任务的不同部分。 例如,以下是一个示例Bash脚本,用于执行作业的一个子任务: #!/bin/bash # Get the subtask ID from the command line arguments subtask_id=$1 # Execute the subtask calculation ./my_job_calculation –subtask $subtask_id “` 在这个例子中,脚本使用命令行参数 `$1` 获取子任务的ID,然后调用实际的计算命令来执行该子任务的计算。
3. 提交作业:使用bsub命令提交主作业脚本。例如: bsub -J my_job -o my_job.out -e my_job.err my_job.sh 这将将主作业脚本“my_job.sh”提交到LSF中。LSF将在后台运行该脚本,并将作业拆分为多个子任务,每个子任务都使用单独的Job名称和输出/错误日志文件。 您可以使用`bjobs`命令查看作业的状态和进度,以及每个子任务的状态和进度。
在LSF中提交作业分多个子任务可以提高作业的运行效率,但也需要考虑到作业拆分和并行计算带来的额外复杂性。如果您不熟悉并行计算技术,建议先学习相关的基础知识,以便更好地设计和管理并行作业。
bsub -J job_name 和 bsub -J “job_name[index_list]%job_slot_limit” 是 bsub 命令的选项,用于指定作业(job)的名称。具体含义如下:
• bsub -J job_name :将作业的名称设置为 job_name。
• bsub -J “job_name[index_list]%job_slot_limit” :将作业的名称设置为 job_name,并指定作业数组的索引范围为 index_list,以及每个作业数组元素可使用的最大计算资源数为 job_slot_limit。
其中,作业数组是一组具有相同作业名称的作业的集合。在作业数组中,每个作业都有一个唯一的整数索引,可以使用这个索引来标识作业。作业数组可以方便地管理一组类似的作业,例如同种任务的多个实例。
例如,bsub -J “myjob[1-4]%2” 将创建一个名为 myjob 的作业数组,包含4个作业元素,索引分别为 1、2、3、4。每个作业元素可以使用最多2个计算资源。这意味着,每个作业元素只能在最多2个计算节点上运行。如果有多个计算节点可用,这个作业数组的作业元素将按照可用资源的数量进行分配和调度。
测试: 我提交一个名为myjob的job分1-10个数组索引到long_q这个队列 ,同时可以并行3个计算资源,等3个任务跑完会继续跑下面的任务;
提交命令
运行过程
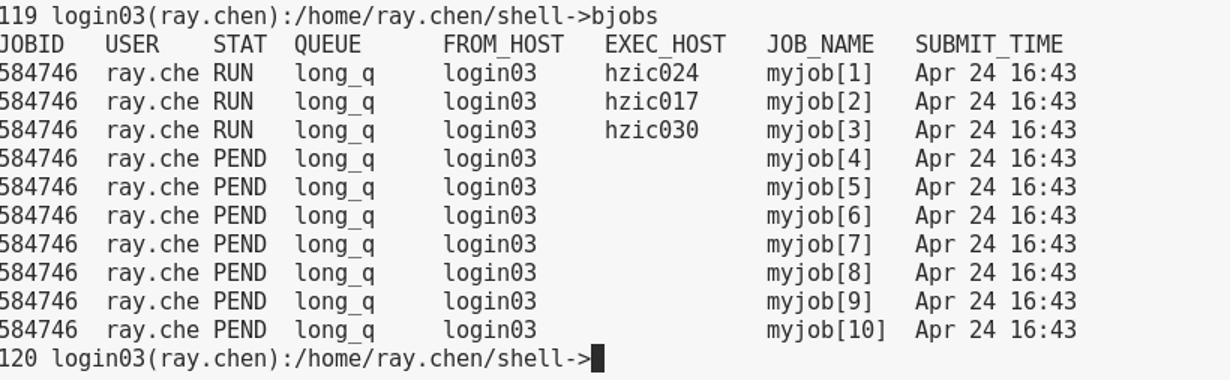
运行结果